HANA News Blog
Golden Rules for HANA Partitioning

Partitioning is not only useful to get rid of the record limitation alerts ID 17 ("Record count of non-partitioned column-store tables"),
20 ("Table growth of non-partitioned column-store tables") or 27 ("Record count of column-store table partitions") it can improve performance of SQLs,
startup, HSR, data migration and recovery. It is also useful to have a proper design to make use of NSE with paging out range partitions which are not frequently used.
I have also seen quite many of wrong designs like using multiple columns as partition attribute, too big or too small partitions, partitions with too many empty partitions. It can also happen that a design which is currently totally correct is not scalable and has bad performance due to massive change rate (increase due to growth as well as decrease due to archiving). This means you have to monitor the SQLs and the change rate and rate your partition design after 8-12 months again. Also due too new features (dyn. range partitioning / dynamic aging: threshold, interval + distance) it can make sense to redesign the partitioning. It is a moving target and like building a house - it will never be 100% complete and fitting your requirements, because the requirements will change over time.
Overall it is a very complex topic which should only handled by experts. A repartitioning can be really painful due to long downtimes (offline / standard partitioning ) or impacting the business due to long runtimes and resource consumption (online partitioning).
Rule of thumbs
Rule of thumbs for the initial partitioning:
- min. 100 mio entries per partition for initial partitioning
- max. 500 mio entries per partition for initial partitioning
- if you choose too many partitions you can achieve a bad performance, because one thread per partition have to be triggered (e.g. you have 20 threads as statement concurrency limit and 40 partition have to be scanned which results in waiting for resources)
- if you choose too less partitions, it can be that you have to repartition pretty timely which means another maintenance window / downtime
- recommendation: HASH partitioning on a selective column, typically part of primary key
- making sure that a single partition doesn't exceed a size of about 25 to 30 GB due to delta merge performance (SAP note
2100010)
- not too many empty partitions
Some of this rules can be checked by using the mini checks of SAP note 1969700.
For every rule exists a exception. For example ACDOCA can have (due to its number of fields which change over time depending on the S/4HANA release) a partition size up to 100GB (SAP note 2044468). You will be charged in case of a delta merge, but if pruning is not possible is does make sense not to split this partition. This depends on the filters with the parallel threads required, as well as the number of parallel executions and business criticality.
It always depends on the usage of your system. There is no general design which is valid for every customer. You always need a detailed analyses and also this has to be done frequently because the workload and also the SQL (incl. filters) can change over time.
More details in one of our presentations at HANA Tech Con 2025
HASH
Use HASH partitioning if you have not a number, id or interval which is constantly increasing and used by the SQLs where clauses. If you are not aware of
the change rate and distribution, you can use HASH partitioning as a safe harbor. But use the number of partitions wisely! You can not easily add
partitions like for RANGE partitioning. The scalability is limited. A repartitioning can be expensive! Create the number of partitions wisely not too many and not too less.
RANGE
Use RANGE partitioning if you have a time attribute or a change number. This means a integer value which is constantly increasing and used by the SQLs
where clauses.
Typical date/time fields (in ABAP dictionary the data type is another one compared to HANA DB):
GJAHR (4 chars, ABAP DDIC: NUMC, HANA : NVARCHAR)
UDATE (8 chars, ABAP DDIC: DATS, HANA : NVARCHAR)
TIMESTAMP (21 chars, ABAP DDIC: DEC, HANA : DECIMAL)
Typical other integer fields which can be used for RANGE partitioning (sure there are more):
KNUMV
CHANGENR
This means not that every table with such columns should be partitioned by this attributes. It depends on the distribution and selectivity. Every system is different and there is no silver bullet.
The advantage of RANGE partitioning is, that you can add new partitions within milliseconds without disturbing the business operations. It means RANGE partitioning is the smarter partitioning option. You can also rebalance the design by merging or splitting partitions. During the partitioning process only the defined and affected ranges will be touched. This allows you to redesign the partitioning without big downtimes. This applies to standard/offline partitioning. For online partitioning always the complete table has to be touched!
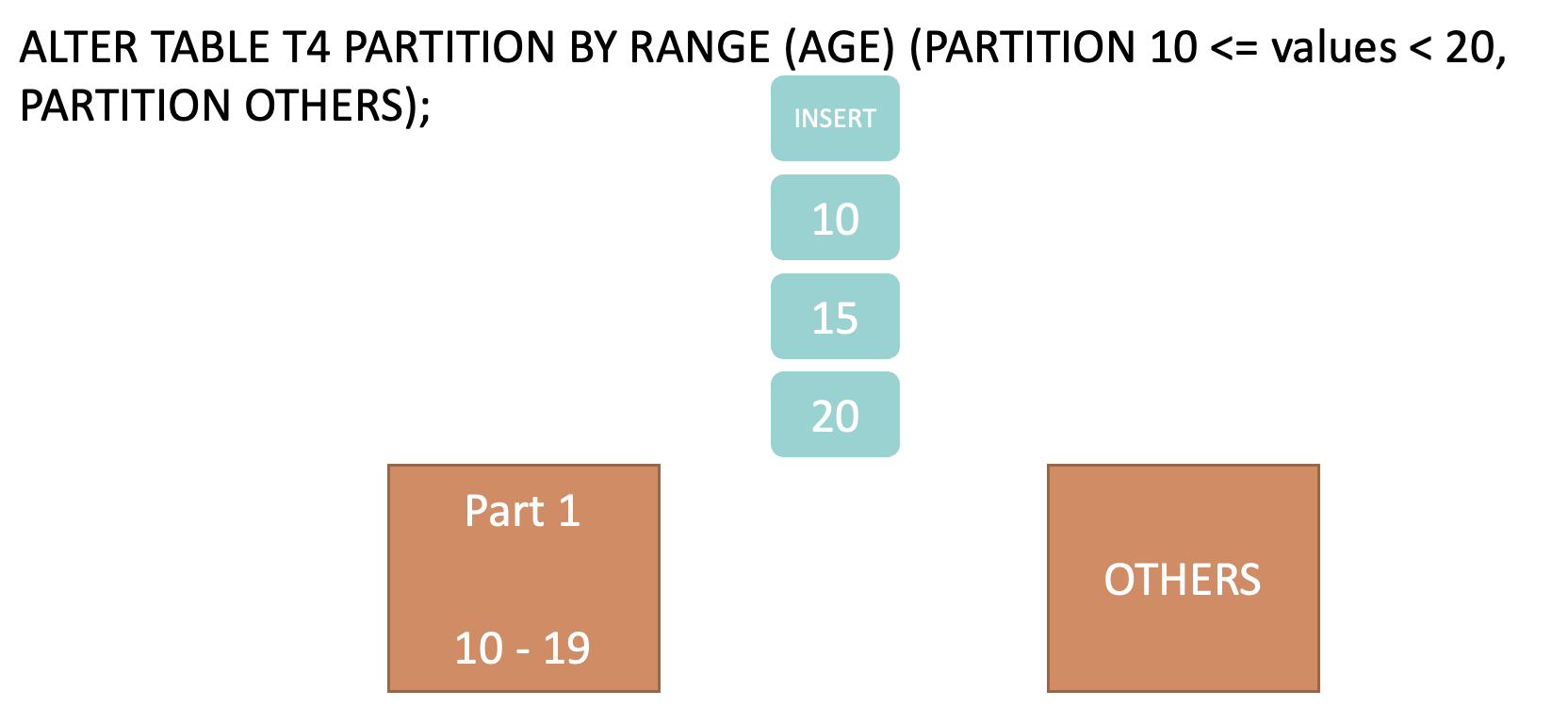
RANGE partitioning includes also in all normal cases a OTHERS partition which all data will be stored which has no valid range. There are some features regarding dynamic range options (threshold and
interval option) which will be handled in an own article.
Multilevel partitioning
If your system includes huge tables it might be wise to use more than one attribute. One on the first level and one on the second level. This depends on the affected table and columns if it makes sense or not. There are only rare scenarios where it makes sense to combine multiple attributes on one level.
Designing Partitions
Actually the online repartitioning is based on table replication. Tables with the naming convention _SYS_OMR_<source_table>#<id> are used as interim
tables during online repartitioning operations. For details please read the “Designing Partitions” section in the documentation.
Summary:
- Use partitioning columns that are often used in WHERE clauses for partition pruning
- If you don’t know which partition scheme to use, start with hash partitioning
- Use as many columns in the hash partitioning as required for good load balancing, but try to use only those columns that are typically used in requests
- Queries do not necessarily become faster when smaller partitions are searched. Often queries make use of indexes and the table or partition size is
- not significant. If the search criterion is not selective though, partition size does matter.
- Using time-based partitioning often involves the use of hash-range partitioning with range on a date column
- If you split an index (SAP names the CS tables also as index), always use a multiple of the source parts (for example 2 to 4 partitions). This way the
- split will be executed in parallel mode and also does not require parts to be moved to a single server first.
- Do not split/merge a table unless necessary.
- Ideally tables have a time criterion in the primary key. This can then be used for time-based partitioning.
- Single level partitioning limitation: the limitation of only being able to use key columns as partitioning columns (homogeneous partitioning)
- the client (MANDT/MANDANT) as single attribute for partitioning is not recommended - only useful in multi level partitioning scenarios with real multi clients environments
In the end if you want be on the safe site, just contact us. We will find a scalable design and may improve performance or also find a NSE design for your tables. It is a complex topic on for a proper design you need deep knowledge in SQL performance tuning, partitioning options and HANA is working in general. In the near future our new book will be released with all details regarding partitioning.
Do you need help to raise your knowledge or straight recommendations from an expert? Check out our workshops or the expert services.
SAP HANA News by XLC