HANA News Blog
Is the effort for NSE worth it?
Is NSE worth the effort or is the better question: Do you know your cost per GB of RAM?
Most of our presentations on data tiering projects end with these typical questions:
- How much we will save?
- How fast can it be implemented?
- Is the effort worth it over time?
My counter question:
"Do you know how much 1 GB of memory costs your company per month or year?"
=> how much memory we have to save to be beneficial?
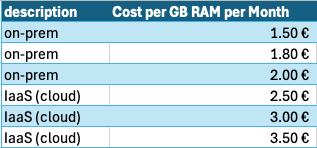
Most of the customers cannot instantly answering this questions due mixed costs (hardware, software, maintenance, extra services, etc.). Do you know yours memory costs? Over the years we collected such data specific only for the infrastructure for on-prem and cloud systems.
For on-prem systems we are in the range of 1.30€ to 2.00€ per GB per month. This means in average 1.80€ (over the number of customers).
For IaaS systems (3 years reserved instances) we are in the range of $0.77 to $4.80 per GB per month for MS Azure (customer average: $2.56) and $1.64 to $5.67 per GB per month for GCP (customer average: $3.47). Please note this not a rating pro or con one of the hyperscalers due to the lag of comparison. You cannot compare the instances 1:1 due to the difference in CPU processor, number of CPUs, interfaces, costs per OS, different contract discounts etc. Please be aware of the concurrency conversion issues from $ to €.
In the end it is an easy calculation. If you save more memory compared to the costs of a data tiering project, you have your benefit and the answer if the effort worth it.
The cost of a NSE project? It depends as always. Mostly we do more than just NSE. We are optimizing partitioning designs, index memory usage and tuning some SQLs. This means not only NSE alone will save the memory but a big part belongs to the NSE benefit.
A NSE project is normally in the range of 15,000 to 30,000€. This means if we assume the max. costs, the benefit of NSE have to be bigger than 30,000€ over time.
How much memory saving you can expect?
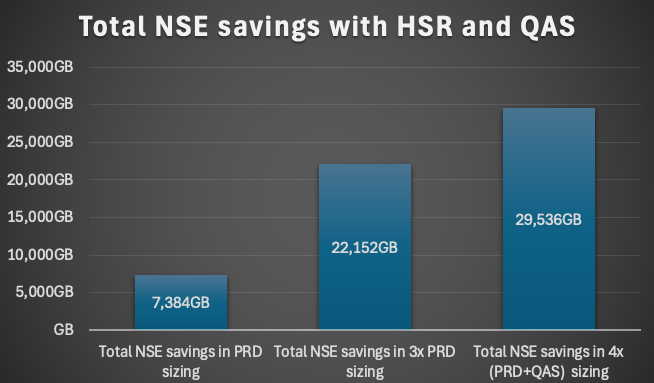
Typically, depending on the archiving strategy, the aggressiveness of the NSE design, and system growth, we achieve savings of 27% to 35% per system. This means for the most customers it includes the PRD, QAS, and even the secondary HANA system replication site. For most environments, you save three times as much memory per NSE project.
If we save 500GB in the HANA sizing which means round about 250-300GB of payload (our smallest project achieved a saving of 600GB in the sizing with costs of around about 13,000€). When we will reach the break even with costs of 30,000€? Do we need multiple years? No! For most of the system we will reach the break even point in less than 10months.


If we assume a saving of 800GB per system in the HANA sizing we would reach the break even point for all systems in 8 months.

As you can see even with "high" NSE project costs you will achieve ROI in about one year.
Rule: The more systems are affected and the more savings can be achieved per system, the faster the investment in an NSE project will pay off.
The best aspect is that not only save system resources and money, you will also improve your energy efficiency and reduce your business’ carbon footprint. With the EU’s CSRD now regulating that compute energy must be measured as an emission, the environmental cost of HANA can soon overshadow its monetary cost.
If you are planning a RISE project you should implement NSE before you migrate to RISE because currently there is no CAS for a NSE design.
SAP HANA News by XLC