HANA News Blog
HANA systems: Linux swappiness
Page Priority
################################
German version (scroll down for English)
################################
Seit SLES15 SP4 und RHEL8 (auch bei anderen Linux Distributionen) hat sich das Verhalten beim Reclaim geändert (Details)
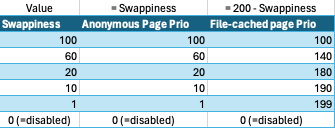
Vorher: vm.swappiness Default 60 [Range: 0 - 100]
Nachher: vm.swappiness Default 60 [Range: 0 - 200]
2 Arten von Pages:
- anonymous page: dynamische Laufzeitdaten wie stack und heap
- FS (Filesystem) page: Payload wie Applikationsdaten, shared libs etc.
Mit einem Wert von 100 wären damit anonymous pages und FS pages gleichgewichtet. Mit 0 - wie bisher auch - wird das swap Verhalten deaktiviert. Je höher also der Wert gesetzt wird, desto höher gewichtet man die anonymous pages. Es wird immer "kalte" Pages geben, welche einmalig in den Speicher geladen wurden und bei denen es Sinn macht sie früher auszulagern bevor der Speicher tatsächlich mal knapp wird.
Details
Früher (vor SLES11 SP3) wurden die anonymous pages nicht in das Verhalten miteinbezogen. Seit dem hatten man eine 1:1 Gewichtung der Kosten (file-cached pages : anonymous pages) eingeführt. Es wurde immer davon ausgegangen die file pages häufiger zu scannen und auszulagern als die anonymous pages, da es als recht teuer und damit als störend empfunden wurde. Es wurde also über Zeit erkannt, dass es in manchen Situationen doch Sinn macht dieses Verhalten zu ändern, daher hat man den Mechanismus granularer gestaltet.
Summary
Am Ende des Tages, wer hätte das gedacht, ist der neue Algorithmus effektiver und sinnvoller, sorgt aber dafür dass es zu höherem Paging Verhalten führt. Das macht aber nichts, da die Pages die ausgelagert werden tatsächlich mehr als "kalt" sind. Es muss sich also keiner Sorgen machen der bei gleichem Workload und Sizing nun erhöhtes Swapaufkommen bemerkt. Dazu gibt es auch neue metriken in vmstat mit denen sich das Verhalten monitoren lässt.
Empfehlung
Wenn es also viel I/O im System anliegt und der Anteil von FS pages gering ist, kann eine Erhöhung des vm.swappiness Parameters die Performance positiv beeinflussen. Daher empfehle ich den Parameter bei SLES15 SP4+ _nicht_ auf 0 oder 1 zu setzen. Tests haben gezeigt, dass sich mit dem Wert von 10 am besten mit HANA und dem damit verbunden Workload arbeiten lässt, allerdings kann auch ein höherer Wert dienlich sein (10 - 45 aus meinen Tests), da es darauf ankommt welche Third-Party Tools auf dem System zusätzlich laufen (AV, backup, monitoring etc.). Dies kann nur mit Tests und längeren Analysen beantwortet werden.
Fazit
Bleibt aber die Frage nach dem richtigen Monitoring offen. Früher hat man alarmiert sobald swap space genutzt wurde, da man davon aus ging, dass ein Speicherengpass vorliegt. Diese Frage muss sich nun jeder selbst stellen und für sich beantworten. Welche Metriken wurden dafür benutzt? Ab welchen Schwellwert alarmiere ich anhand der neuen Metriken? Kann mein Monitoring Tool diese neuen Metriken auslesen? Muss ich mir eine custom Lösung bauen? All das ist abhängig von der aktuellen Monitoringlösung.
################################
English version
################################
Since SLES15 SP4 and RHEL8(also in other Linux distributions) the behavior of reclaim has changed (details)
Before: vm.swappiness Default 60 [Range: 0 - 100]
After: vm.swappiness Default 60 [Range: 0 - 200]
2 types of pages:
- anonymous page: dynamic runtime data such as stack and heap
- FS (Filesystem) page: Payload such as application data, shared libs etc.
With a value of 100, anonymous pages and FS pages would be weighted equally. With 0 - as before - the swap behavior is deactivated. The higher the value is set, the higher the anonymous pages are weighted. There will always be "cold" pages that have been loaded into memory once and for which it makes sense to swap them out earlier before the memory actually runs out.
Details
Previously (before SLES11 SP3) anonymous pages were not included in the behavior. Since then, a 1:1 cost weighting (file-cached pages: anonymous pages) has been introduced. It was always assumed that the file pages would be scanned and outsourced more frequently than the anonymous pages, as it was perceived as quite expensive and therefore annoying. Over time it was recognized that in some situations it makes sense to change this behavior, so the mechanism was made more granular.
Summary
At the end of the day, who would have thought, the new algorithm is more effective and sensible, but ensures that it leads to higher paging behavior. But that doesn't matter because the pages that are being swapped out are actually more than "cold". So no one has to worry about noticing increased swap volumes with the same workload and sizing. There are also new metrics in vmstat that can be used to monitor behavior.
Recommendation
So if there is a lot of I/O in the system and the proportion of FS pages is low, increasing the vm.swappiness parameter can have a positive effect on performance. I therefore recommend not setting the parameter to 0 or 1 for SLES15 SP4+. Tests have shown that a value of 10 is best for working with HANA and the associated workload, although a higher value can also be useful (10 - 45 from my tests), as it depends on which third-party tools are used also run on the system (AV, backup, monitoring, etc.). This can only be answered with tests and longer analyses.
Conclusion
However, the question of the correct monitoring remains open. In the past, an alarm was raised as soon as swap space was used because it was assumed that there was a memory bottleneck. Everyone has to ask themselves this question and answer it for themselves. What metrics were used for this? At what threshold do I alert based on the new metrics? Can my monitoring tool read these new metrics? Do I have to build a custom solution? All of this depends on the current monitoring solution.
SAP HANA News by XLC