HANA News Blog
HANA Sequences - die verborgene Handbremse im System
Nutzung von Sequences
Verwenden sie in ihren SAP HANA Systemen Sequences? Das sollte unbedingt geprüft werden. Diese können bei nicht korrekter Einrichtung die Performance einzelner SQL-Statements stark beeinflussen. Eine HANA Sequence kann mit einem fortlaufenden Nummernkreis im ABAP verglichen werden. Die Sequence generiert eindeutige, vorlaufende Nummern, die z. B. von einem HANA Trigger oder beim INSERT in eine Tabelle verwendet werden können. Ähnlich wie im ABAP können Nummern gepuffert werden. Im Standard ist der Cache jedoch auf 1 eingestellt.
Greifen gleichzeitig viele Operationen auf die Sequence zu, kommt es zu Wartesituation, bis die nächste Nummer vergeben wird. Durch Erhöhung des Sequence Cache kann dieses Problem gelöst werden. Hinweis: Durch den Einsatz des Caches kann es Lücken in der Vergabe geben, jedoch sind die Nummern immer fortlaufend.
Wie prüfe ich, ob Entwickler oder gar Third-Party Hersteller HANA Sequences benutzen?
Sequence im Statement erkennen:
Im Statement ist die Sequence durch die Funktion “.NEXTVAL” zu erkennen.

Beispiel mit Trigger:
Der Trigger, welcher wiederum eine Sequence verwendet, macht circa 90 % der Laufzeit des Statements aus. Hier zu sehen im Kontext der Child Prozesse.

Kernel Profiler
Statement Collector des Trigger Statements
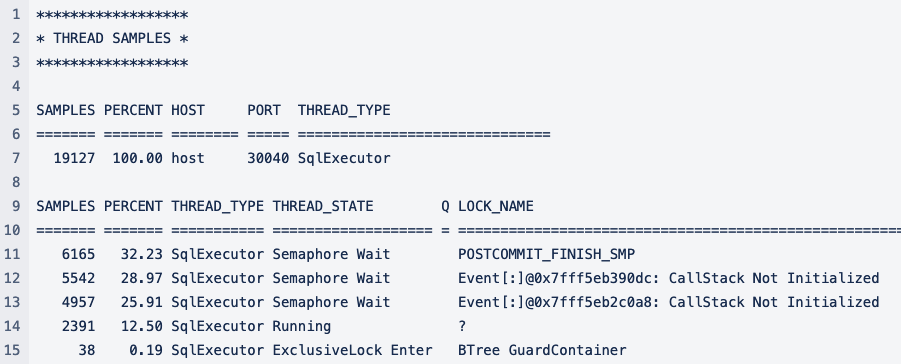
CallStack Not Initialized
: This is a generic, unspecific semaphore name used for various semaphores in IBM on Power environments. On Intel they follow the naming convention "<module>.cpp: <function>" instead, e.g. "DeltaIndexManager.cpp: TRexAPI::DeltaIndexManager::MergeAttributeThread::MergeAttributeThread".
Mittels Kernel Profiler kann ermittelt werden, was genau die DB in diesem Status macht. Das gilt auch für andere Fälle.

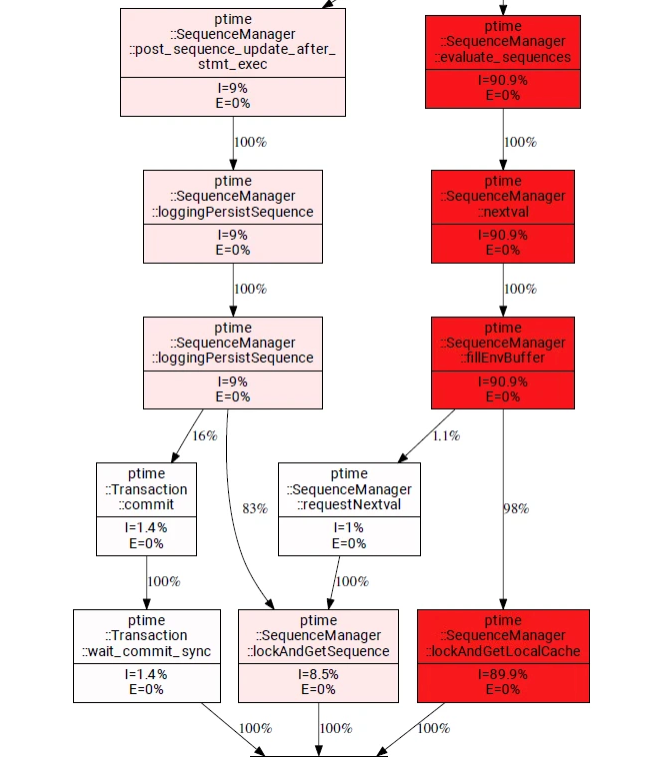
3,88s Wartezeit
Davon entfallen über 90% auf die HANA Sequence
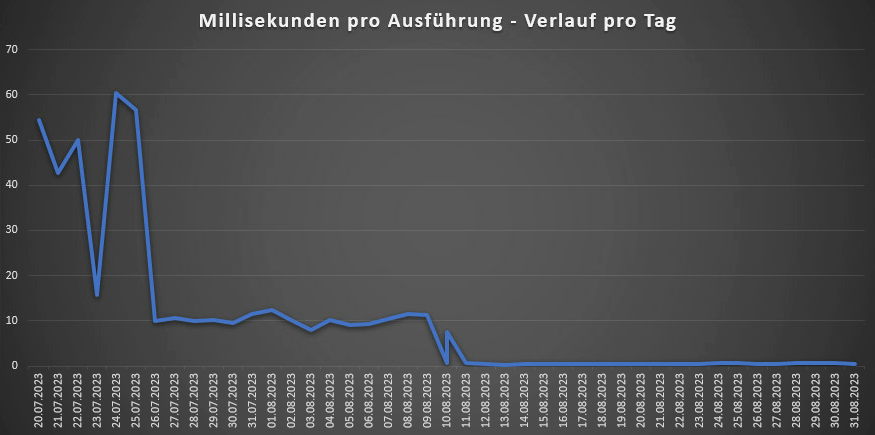
Beim konkreten Kundenfall hatte das folgenden Effekt:
Peakzeiten vor Caching: 160ms pro Ausführung
Peakzeiten nach Caching: 1ms pro Ausführung
Im täglichen Durchschnitt sieht der Ergebnis folgendermaßen aus:
SAP HANA News by XLC