HANA News Blog
HANA Plan Stability
Abstract SQL plan capturing
The feature plan stability is not a new one, but can help you in case of an revision update/upgrade, if you recognize big performance degradations. But you have to activate this feature at least 1-2 weeks before the maintenance to capture the SQLs and the execution plan. You can compare the plan performance and apply the execution plan with the best performance. You can also use it as always on feature in daily operations. This may be required due to changes in data over time which may cause the query optimizer to propose different execution plans which may have a negative impact on performance and memory consumption of a query. An additional preparation step can be used to apply filters so that only specific queries are captured. In the background execution statistics are recorded so that the performance of the query can be measured and the best execution plan can be selected.
Please don't forget to migrate the abstract SQL plan (ASP) after an upgrade:
ALTER SYSTEM MIGRATE ABSTRACT SQL PLAN;
For some scenarios it is currently not possible to use the abstract plan feature e.g. FDA queries, SqlScript Optimizer, MDX, CDS (partially supported from CE2022/QRC01) or even HEX (SAP is planning HEX as the next generation execution replacing existing legacy engines and only plan to capture HEX based execution plans). For the on prem variant it is only possible to capture complex statements. For HANA Cloud it is also possible to capture simple statement characteristics starting with 2022.QRC02 :
ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'system' ) SET ('abstract_sql_plan', 'capture_simple_queries') = 'true' WITH RECONFIGURE;
Keep also in mind that any change on the metadata version information of related object will invalidate the Abstract SQL Plan. This means it cannot be applied if e.g. an alter table command was executed like a repartitioning.
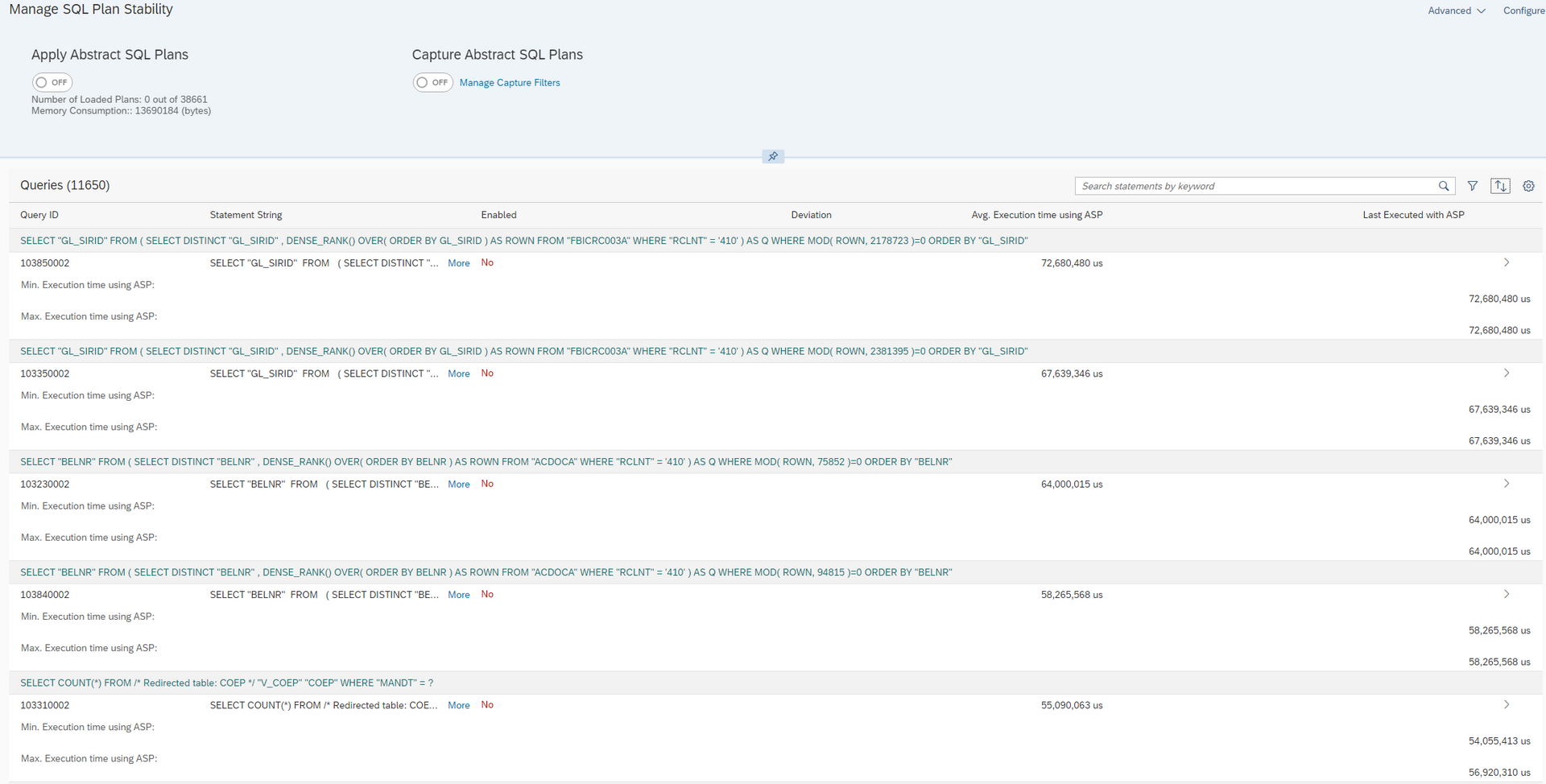
You can easily activate the feature via HANA Cockpit:
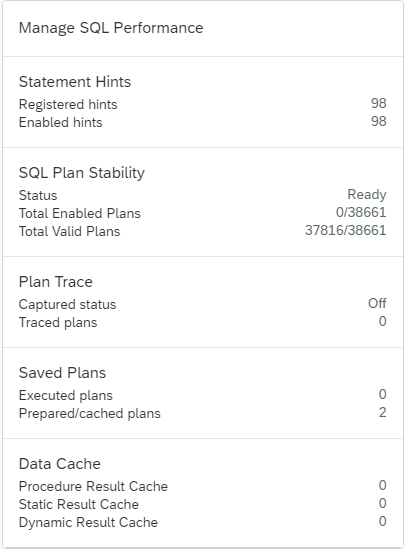
Neuer TextHere some parameters which can influence the resources:

© 2023 SAP SE or an SAP affiliate company. All rights reserved.
SAP HANA News by XLC